Failover Clustering setup in Postgres
Blogs
Disaster Recovery setup in Postgres
November 24, 2025
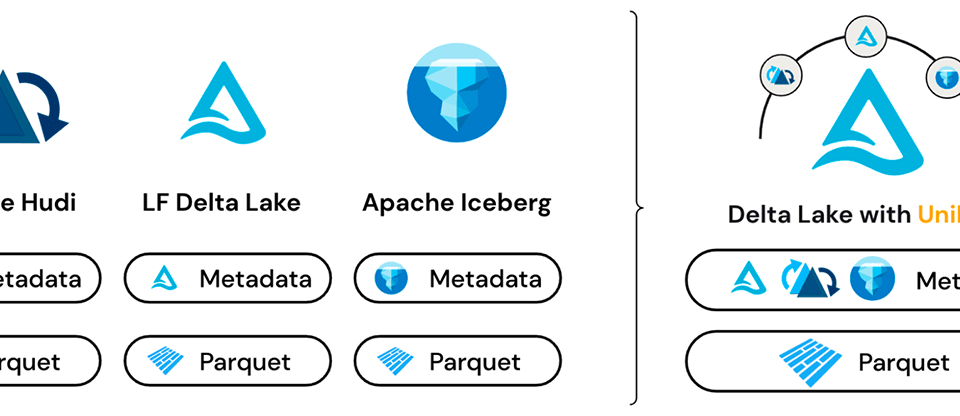
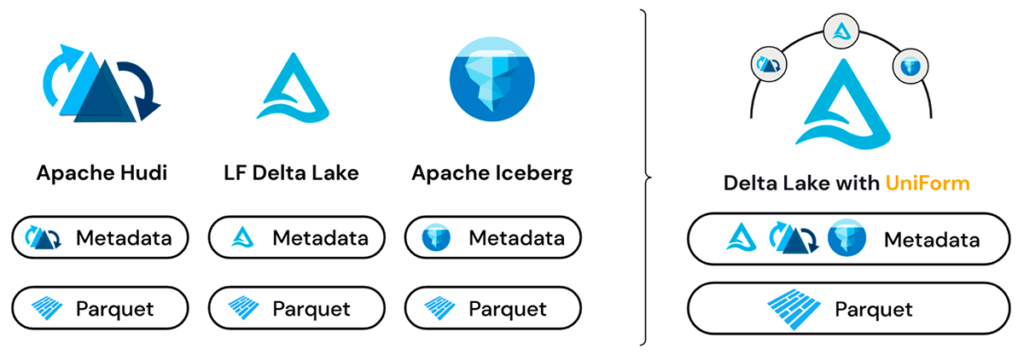
Delta UniForm: One Table, Every Tool
March 10, 2026Failover Clustering setup in Postgres
High availability for PostgreSQL can be achieved through several architectures. While tools like Patroni provide automated failover with distributed consensus, many enterprises prefer a more traditional cluster approach based on a proven high-availability stack: Pacemaker and Corosync.
In this article, we walk through how to build a two-node PostgreSQL failover cluster using Pacemaker, Corosync, a Virtual IP (VIP), and Azure Load Balancer. This approach is very similar to how Failover Cluster Instances (FCIs) work in environments such as SQL Server, but implemented using Linux HA technologies.
The result is a classic active-passive failover cluster, where one node runs PostgreSQL at any given time, and the second node takes over automatically if the primary node fails.
Architecture Overview
The architecture consists of the following components:
Node 1: PostgreSQL + Pacemaker/Corosync
This is the active node during normal operation. PostgreSQL runs here, and Pacemaker manages it as a cluster resource.
Node 2: PostgreSQL + Pacemaker/Corosync
This is the passive (standby) node. PostgreSQL is installed but not running unless a failover occurs. Pacemaker controls the service during a failover event.
Cluster Stack: Pacemaker + Corosync
The two nodes communicate using Corosync for cluster membership, heartbeat, and fencing decisions. Pacemaker manages the PostgreSQL resource, detects failures, and handles the promotion of the second node during failover.
Virtual IP (VIP)
A floating IP address that Pacemaker assigns to whichever node is currently active. Client applications connect to this IP instead of a physical machine’s IP, ensuring continuity during failover.
Azure Load Balancer (Optional but Recommended)
Azure Load Balancer is used to safely host a virtual IP address in the cloud environment, because Azure does not support gratuitous ARP or IP takeover natively. By using a load balancer with a health probe, the VIP becomes stable and cloud-compatible.
Role of Each Component
Corosync
Corosync handles communication between cluster nodes. It provides:
-
Heartbeat signals
-
Membership tracking
-
Failure detection
-
Messaging between nodes
It ensures the two nodes maintain an accurate view of each other’s health.
Pacemaker
Pacemaker is the cluster resource manager. It performs:
-
Starting PostgreSQL on the active node
-
Monitoring PostgreSQL health
-
Stopping PostgreSQL on failover
-
Restarting PostgreSQL on the secondary node
-
Managing the Virtual IP resource
Pacemaker uses Corosync’s membership information to decide cluster actions safely.
PostgreSQL
PostgreSQL is installed on both nodes, but it runs only on whichever node Pacemaker designates as the active node. Data is stored on shared storage or replicated using a block-level replication mechanism such as DRBD, depending on the design. Many Azure-based deployments use managed disks detached/attached by the cluster, or synchronous storage.
Virtual IP
The virtual IP provides a single client connection endpoint. Because the VIP moves with the PostgreSQL service, applications do not need to change connection strings during failover.
Azure Load Balancer
In Azure, IP failover does not work the same way as on traditional networks. Azure Load Balancer provides:
-
A frontend IP that acts as the VIP
-
Health probe pointing to the active node
-
Backend configuration mapping both nodes
-
Failover routing depending on heartbeat response
Pacemaker modifies the health probe listener on the active node so that Azure LB knows which VM should route traffic.
Cluster Workflow
The failover sequence works as follows:
-
Corosync runs on both nodes and maintains cluster heartbeat.
-
Pacemaker manages PostgreSQL and VIP as resources.
-
If Node 1 is healthy, Pacemaker starts PostgreSQL and binds the VIP to Node 1.
-
Azure Load Balancer probes Node 1 and routes traffic to it.
-
If Node 1 stops responding or PostgreSQL becomes unhealthy, Pacemaker:
-
Stops PostgreSQL on Node 1
-
Starts PostgreSQL on Node 2
-
Moves the VIP to Node 2
-
-
Azure Load Balancer detects the probe change and begins routing traffic to Node 2.
-
Once Node 1 is repaired, it rejoins as a passive node.
This creates a predictable, controlled failover mechanism.
Step-by-Step Deployment
Below is a condensed description of how the cluster is configured.
1. Install Required Packages on Both Nodes
Enable the HAC cluster stack:
Set the hacluster password on both nodes:
2. Authenticate Nodes for Cluster Creation
Run on one of the nodes:
3. Create and Start the Cluster
4. Configure STONITH / Fencing
Fencing (node isolation) must be enabled for safe operation:
This prevents split-brain during failover.
5. Add the Virtual IP Resource
Note: In Azure, this VIP typically corresponds to an Azure Load Balancer’s frontend IP.
6. Create the PostgreSQL Resource
Pacemaker manages PostgreSQL using resource agents:
7. Create a Resource Group
Combine VIP and PostgreSQL into a failover unit:
This ensures VIP moves with PostgreSQL during a failover.
8. Configure Azure Load Balancer
Azure Load Balancer is configured with:
-
A frontend IP matching the VIP
-
Backend pool including both cluster nodes
-
A health probe on a custom port
-
Load-balancing rule that forwards PostgreSQL traffic
On the active node:
Pacemaker binds the probe listening port so that Azure LB directs traffic to it.
Failover Testing
-
Verify the current cluster status:
-
Stop PostgreSQL on Node 1:
Expected behavior:
-
Pacemaker detects the failure.
-
VIP is moved to Node 2.
-
PostgreSQL starts on Node 2.
-
Azure Load Balancer updates routing.
-
Start Node 1 service back to normal:
Node 1 becomes the passive node until required again.
Conclusion
This two-node PostgreSQL setup using Pacemaker, Corosync, Virtual IP, and Azure Load Balancer provides a traditional and reliable high availability environment. The stack is mature, stable, and widely used in enterprise infrastructures. By integrating Azure Load Balancer, the architecture becomes fully cloud-compliant while retaining classic failover behavior.
Lochan R

{kind=link}