Handling Token in OpenAI
Blogs

How to setup transactional replication when the publisher is part of Always On Availability Group
December 4, 2023Unlocking MAXDOP of SQL Server: Tuning Query Performance for Complex Workloads
December 17, 2023Handling Token in OpenAI
OpenAI is an advanced Artificial Intelligence platform that utilises machine learning models to provide efficient responses to the user inputs. It offers an API that allows users to access OpenAI’s capabilities and leverage its fine-tuning feature. This feature enables the customisation of the AI models to better suit specific use cases and requirements. By utilising OpenAI, users can benefit from the power of AI and enhance their applications with intelligent responses and interactions.
Handling tokens effectively in OpenAI is crucial to ensure that text stays within the model’s limits, here are step to manage tokens:
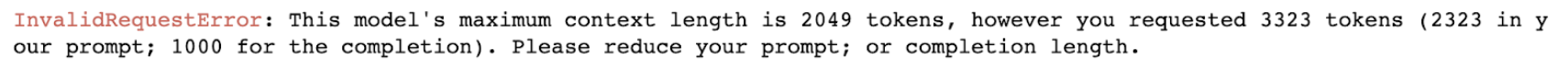
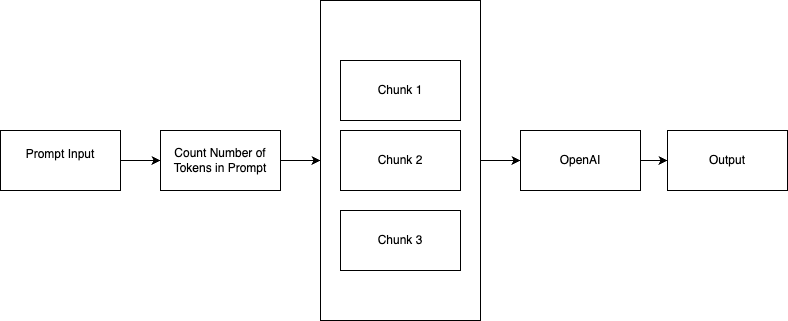
Understand Token Limits:
- Each API call to OpenAI consumes a certain number of tokens.
- The total number of tokens (input + output) must not exceed the maximum limit allowed by the specific OpenAI model you are using.
- If the token count exceeds the maximum threshold of the model tokens, we will encounter an error “The maximum context length allowed in OpenAI is XXX tokens. It is important to manage the token count effectively to ensure that your text remains within these limits.”
Counting Tokens:
- Use OpenAI’s
tiktokenPython library to count tokens in a text string without making an API call.

Trimming Text:
- If text token exceeds the token limit, then we need to truncate, omit, or summarise text.
Batching Requests:
- Split longer input into smaller chunks.
- Send multiple requests to the API and concatenate the responses.

Experiment with Temperature and Max Tokens:
- Adjust the temperature parameter during API calls to control randomness in responses.
- Set a reasonable value for
max_tokensto limit the length of generated output.
Use System and User Messages Wisely:
- System messages (e.g., instructions to the model) and user messages both contribute to token count.
- Balance the use of these messages to stay within token limits.
Optimize Input for Context:
- Focus on providing relevant context in the input prompt.
- If the model struggles to understand, consider providing additional context or rephrasing the input.
Fine-tuning:
- If you have specific requirements, consider fine-tuning the model to better suit your use case.
Handle API Errors Gracefully:
- Implement error handling in your code to manage cases where the token limit is exceeded.
- Adjust your input accordingly and retry if necessary.
Regularly Check Model Specifications:
- Stay updated on any changes or updates to the OpenAI models.
- Check the OpenAI documentation for the latest information on token limits and best practices.
Poornima N



{kind=link}