Implementing Semantic Search in Elasticsearch
Blogs
Integrating IIS Logs into Apache Druid for Real-Time Analytics
February 14, 2024SuperSpark: Union of Distributed SQL Engine and Self-Serve Analytics Service
February 21, 2024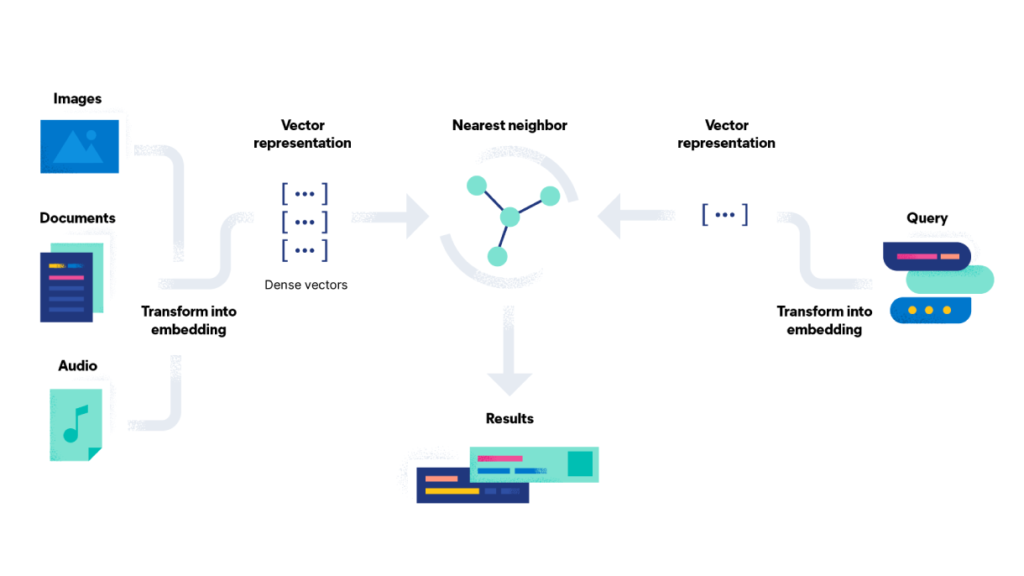
Semantic search is a powerful technique used to retrieve accurate and relevant data by understanding the contextual meaning of words and the intent behind the query.
In this blog post, we will explore semantic search and how to implement it in Elasticsearch.
Elasticsearch:
Elasticsearch is an open-source search and analytics engine designed to handle large volumes of data efficiently. It uses a distributed architecture to horizontally scale across servers, making it suitable for various data types and use cases including text, numerical, geospatial, structured, and unstructured data. Elasticsearch offers diverse functionalities such as security, monitoring, alerting, SQL querying, time series data management, and machine learning.
Elasticsearch Relevance Engine:
The Elasticsearch Relevance Engine is specifically designed for AI-based search applications. It integrates seamlessly with semantic search techniques and supports advanced features such as semantic similarity scoring.
Sentence Transformers:
Sentence Transformers is a Python framework used for text and image embedding. It plays a crucial role in semantic search by encoding textual data into vector representations, facilitating context matching and text search.
Implementation Steps:
-
Install and Import dependency libraries, i.e, Sentence-Transformers and Elasticsearch Python client.
pip install sentence-transformers elasticsearch pandas numpyfrom sentence_transformers import SentenceTransformer
from elasticsearch import Elasticsearch
import pandas as pd
import numpy as np -
Load Sample Dataset:
df = pd.read_csv('sample_dataset.csv')
-
Encode Sentences with Sentence Transformers
model = SentenceTransformer("all-MiniLM-L6-v2")
df['embeddings'] = model.encode(df['sentence'])
-
Establish Connection to Elasticsearch
es = Elasticsearch(hosts="http://localhost:9200", basic_auth=('username', 'password')) -
Check connection is success:
es.ping()If value
True, connection to elastic search is success. -
Configure Elasticsearch Index Settings
"configurations ="{
"settings":{
"analysis":{
"filter":{
"ngram_filter":{
"type":"edge_ngram",
"min_gram":2,
"max_gram":15
},
"english_stop":{
"type":"stop",
"stopwords":"_english_"
},
"english_keywords":{
"type":"keyword_marker",
"keywords":[
"example"
] },
"english_stemmer":{
"type":"stemmer",
"language":"english"
},
"english_possessive_stemmer":{
"type":"stemmer",
"language":"possessive_english"
}
},
"analyzer":{
"en_analyzer":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase",
"ngram_filter",
"english_stemmer",
"english_possessive_stemmer",
"english_stop""english_keywords"
] }
}
}
},
"mappings":{
"properties":{
"Embeddings":{
"type":"dense_vector",
"dims":512,
"index":true,
"similarity":"cosine"
}
}
}
} "type": The parameter should always be set to “dense_vector” to inform Elasticsearch that the field contains vectors and prevent Elasticsearch from assigning a floating-point type to this field."dims": Also known as dimensions, this parameter specifies the dimensionality of the vectors. For instance, if we’re using a Universal Sentence Encoder that produces output vectors of 512 dimensions, we specify “512” for this parameter."index": Setting this parameter to “True” ensures that the field is created and indexed as a dense_vector type in Elasticsearch, allowing for efficient storage and retrieval of vector data."similarity": This parameter specifies the similarity metric to be used for comparing vectors. In this case, we’re opting for cosine similarity, but other similarity metrics can be chosen based on the specific requirements.-
Create Elasticsearch Index
es.indices.create(index='semantic_search', body=configurations) -
Define Query for Semantic Search
query = {
"knn" : {
"field" : "user_input_vector",
"query_vector" : vector_user_input,
"k" : 2,
"num_candidates" : 1000,
},
"_source": [ "user_input"] }"knn": Elasticsearch natively supports the k-Nearest Neighbors (kNN) algorithm, eliminating the need for separate training. This allows for efficient similarity search based on vector embeddings."field": This parameter specifies the field in Elasticsearch where the vector embeddings are stored. Elasticsearch uses this field to perform kNN search and retrieve relevant documents."query_vector": Here, you provide your input query in vector or embedding form. Elasticsearch compares this query vector with the vectors stored in the specified field to find the most similar documents."k": The parameter “k” determines the number of nearest neighbors or search results you want to retrieve. Elasticsearch returns the top k documents that are most similar to the input query vector."num_candidates": This parameter defines the length of the candidate list considered during the kNN search process. A larger value for “num_candidates” can improve recall but may also increase computational overhead."_source": This parameter specifies the field from which Elasticsearch should provide the output or search results. It ensures that only relevant fields are returned in the search results, improving efficiency.
-
Execute the query:
res = es.search(index='semantic_search', body={"query": query})
# Process search results
if res['hits']['total']['value'] > 0:
for hit in res['hits']['hits']:
print(hit['_source']['sentence'])
else:
print("No relevant results found.")
Implementing semantic search in Elasticsearch enhances the search capability and relevance of search results by understanding the contextual meaning of queries. By leveraging technologies such as Sentence Transformers and Elasticsearch’s built-in functionalities.
Poornima N
{kind=link}