Investigating Identity Column Jumps in SQL Server 2019
Blogs
Exploring Change Data Capture in Azure Data Factory
October 2, 2023
ADW TO DELTA MIGRATION
November 5, 2023
In the world of database management, a seamless transition from one SQL Server version to another is a goal that many organizations aim to achieve. However, sometimes, unexpected challenges can arise during this process. In this blog post, we will delve into a specific issue faced by a customer during their migration from SQL Server 2012 to SQL Server 2019 – identity column jumps.
Identity columns play a crucial role in maintaining data integrity and generating unique identifiers automatically. However, the customer encountered a perplexing problem when their identity column values unexpectedly jumped from 8-digit numbers to 12-digit ones, which was completely unacceptable. In response, they sought assistance in diagnosing the issue and finding a solution. This article outlines the journey to uncover the root cause of identity column jumps and the steps taken to address the problem.
Current Challenges:
Let us delve into the challenges currently faced by the customer.
The main challenge the customer encountered is the occurrence of identity column jumps in SQL Server 2019. Specifically, when attempting to insert data from a non-identity source table into the main table while keeping identity_insert enabled, the identity column’s value unexpectedly jumps from an 8-digit value to a 12-digit value.
Understanding the Default Behavior of Identity Columns:
To comprehend this issue better, let’s first examine the default behavior of identity columns in SQL Server. Identity columns are designed to automatically generate sequential, unique values for each new row inserted into a table. While these values are typically integers, other data types can be used. The critical aspect is that each value is unique within the table and increases incrementally by a specified increment value, known as the identity seed. By default, the identity seed is set to 1, and the identity increment is set to 1, ensuring that each new row receives a value one greater than the previous row.
For instance, if you have a table with an identity column and insert three rows into it, the identity column values would typically be 1, 2, and 3. These values are generated automatically, sparing you the need to specify them during the insert operation.
It’s worth noting that the behavior of an identity column can be altered by modifying its seed and increment values or by enabling specific options like IDENTITY_INSERT, which allows manual insertion of values into the identity column. However, the default behavior remains the automatic generation of sequential numeric values.
Analysis Approach to Identify the Issue:
To investigate the behaviour of the identity column, I conducted three types of analysis testing:
- Identity Behaviour on Backup and Restore:
-
- One avenue explored was how identity columns behave when a database is backed up and then restored to another SQL Server instance. This testing aimed to determine whether identity values are preserved or if changes occur.
- Observations: During the database restoration process, no increment or change in the values of the identity column within the restored tables was observed. This indicates that the identity column remains unaffected by backup and restoration operations. Its values stay consistent, providing a stable identifier for records in the restored database.
- Identity Behaviour on SQL Server Crash:
-
- This testing aimed to understand how the identity column values behave after a server crash and restart.
- Observation:A server crash in SQL Server can impact identity columns, resulting in identity jumps. Such crashes can disrupt the sequential and incremental nature of identity column values.
It was observed that during a server crash, the SQL Server instance may experience an unexpected shutdown or interruption, leading to inconsistencies in the generation and assignment of identity column values. When the server is restarted, identity column values may start from a higher value than expected, causing a noticeable jump in the sequence. To mitigate these consequences, it’s essential to review recovery strategies, implement regular backups, and consider alternative approaches for generating unique identifiers if necessary.
- Identity Behaviour on Subquery in WHERE Clause:
This testing focused on evaluating the behavior of the identity column when used in a subquery within the WHERE clause. The goal was to ensure that the identity column maintains its expected sequence during subquery operations.
A specific query example was provided to illustrate this behavior. In this scenario, the data type comparison in the WHERE clause played a crucial role. When the data types differed between tables, the identity column exhibited unexpected behavior. However, if both data types were the same (int), this behavior did not occur.
Step 1: Create a table and insert records to it as shown below:
create table tbla(a int, b char(100))
go
set nocount on
declare @ret int
set @ret = 0
begin tran
while (@ret < 900000)
begin
set @ret = @ret + 1
insert into tbla values (@ret, @ret)
end
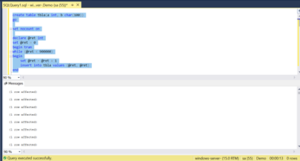
Step 2: Create other two tables and insert records into tbld.
create table tblB(a int identity)
create table tbld(b int)
insert into tbld select top 1000 b from tbla order by a
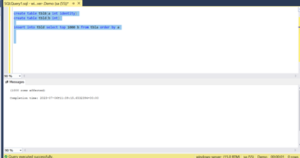
Step 3: Then check the Ident_Current of table tblb.
select IDENT_CURRENT(‘tblb’)
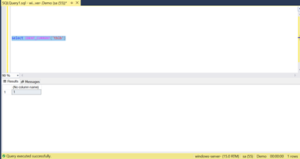
Step 4: Before executing the insert query check the max of all the tables as shown below.
Step 5: Then run the below query to insert the value into the tblb with subquery in the where clause.
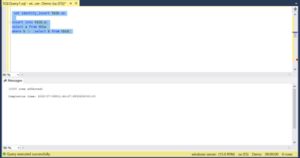
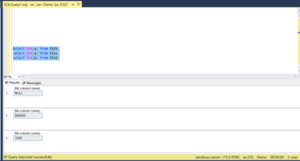
Step 6: Now check the max of table tblb.
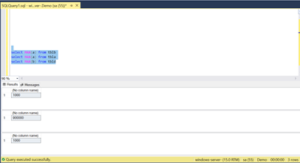
As per identity column behaviour the Current Identity value should be 1000 but if we execute select IDENT_CURRENT(‘tblb’)
We will be notice that the value is not as 1000 its taking the current identity as maximum identity value of the table tblb. As shown below:
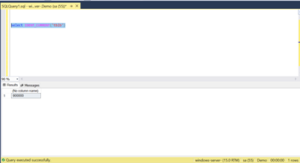
The current identity of the value of the table tblb is coming so because of data type comparison in the where clause.
In, table Tbla column “b” is of char datatype and table tbld column “b” is int.
create table tbla(a int, b char(100))
create table tblb(a int identity)
create table tbld(b int)
Note:But if both the data type are int then this behaviour is not visible.
Below is the Repro script for the demo:
|
Drop table tbla Drop table tblb Drop table tbld
create table tbla(a int, b char(100)) go set nocount on declare @ret int set @ret = 0 begin tran while (@ret < 900000) begin set @ret = @ret + 1 insert into tbla values (@ret, @ret) end
create table tblb(a int identity) create table tbld(b int)
insert into tbld select top 1000 b from tbla order by a
select max(a) from tbla select max(a) from tblb select max(a) from tbld
select IDENT_CURRENT(‘tblb’)
insert into tblb(a) select a from tbla where b in (select b from tbld)
select IDENT_CURRENT(‘tblb’) |
So, after performing all the tests below is the observation:
During the testing process, when attempting to insert data into the table tblb from source tables tbla and tbld using different data types in the WHERE conditions, an unexpected behavior was observed. Specifically, in SQL Server 2019, the current identity value of table tblb was updated with the maximum value from the column ‘a’ present in table tbla. However, this behavior was not observed in SQL Server 2012. It seems this is a bug in the product.
Conclusion:
Migrating databases between SQL Server versions can be challenging, as unexpected issues like identity column jumps may arise. Understanding the intricacies of identity column behavior during backup and restore, server crashes, and subquery operations is crucial for maintaining data consistency and integrity. Database administrators and developers can mitigate the impact of identity jumps by implementing appropriate measures, such as reviewing recovery strategies and ensuring consistent data types when using identity columns. With this knowledge, the mysteries of identity column jumps in SQL Server 2019 can be unraveled, and solutions can be devised to ensure a smooth migration experience.
In the end, knowledge is power. Armed with a deeper understanding of identity column behavior, you can navigate the intricacies of SQL Server with confidence, ensuring that your data remains consistent and reliable throughout your database management journey.
anamika.sar
{kind=link}