SAP CDC Connector in Azure Data Factory
Blogs
Metadata Driven Pipeline Execution
September 18, 2023Exploring Change Data Capture in Azure Data Factory
October 2, 2023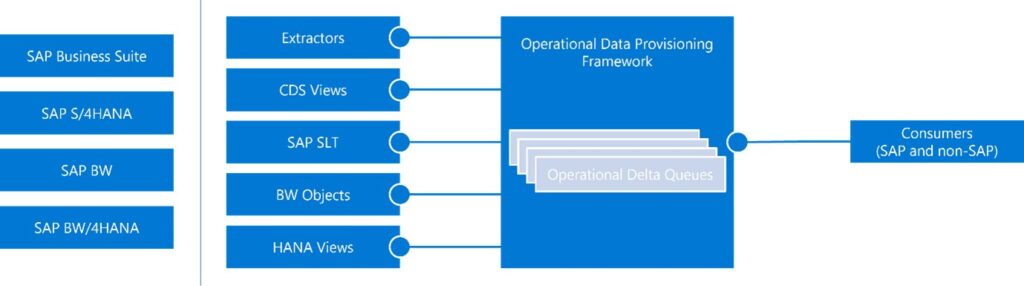
The SAP CDC (Change Data Capture) Connector is a component of Azure Data Factory that enables efficient and reliable extraction of data from SAP systems. It uses the SAP Operational Data Provisioning API to extract data, which allows for high-performance and low-impact extraction of large datasets, including those with millions or billions of rows.
The SAP CDC Connector also offers a significant advantage over traditional SAP Table Connectors, which can be resource-intensive and limit the ability to process entire datasets on a daily basis. The SAP CDC Connector automatically captures and merges incremental changes or delta extracts into a consistent target data store, eliminating the need for full data extraction and providing near real-time data integration.
SAP OPERATIONAL DATA PROVISIONING
The SAP Operational Data Provisioning framework consists of function modules and reports. One of its core functionalities is simplifying the data extraction and replication processes. The improved communication layer ensures the data transfer is reliable and performant. In addition, it takes care of identifying new and changed information in the source objects. If there is a requirement to provide such capability in Azure Data Factory pipeline, you had to create a complex logic that uses watermarks to select relevant data. Comparing creation and changed dates was highly unreliable; moreover, some of the most frequently pulled tables did not even contain such fields.
With SAP Operational Data Provisioning, you don’t have to worry about it at all. The framework works with a set of source SAP objects, including extractors, CDS Views and SLT and manage the extraction process end-to-end. The logic of correct selecting data is already built-in into these objects, so instead of re-creating it, you can focus on delivering value to your business. It’s like outsourcing complex challenges to the source system.
We can distinguish two types of data sources in transactional systems, like SAP S/4HANA or SAP ERP. Tables provide highly normalized data, but they are not so efficient when it comes to analytical scenarios. In such cases, you require additional processing to transform the schema of the data. Instead, you can use Extractors and CDS Views that already provide the data in a multidimensional format and are widely used in SAP Business Warehouse. The SAP Operational Data Provisioning supports both scenarios, but accessing information stored directly in tables requires SAP SLT that uses trigger-based replication to track changes.
The SAP Operational Data Provisioning framework is included in every modern SAP NetWeaver release, but you may need to install some notes or support packages. You can find more information in following SAP Notes:
- 1521883 – ODP Data Replication API 1.0
- 1931427 – ODP Data Replication API 2.0
ARCHITECTURE
Before we dive deep into the configuration, let’s quickly walk through the solution’s architecture and all required components. Azure Data Factory is a cloud service that orchestrates the extraction process but can’t connect directly to the data source. It needs a Self-Hosted Integration Runtime installed on a local server, ideally close to the source SAP system, that provides compute resources to replicate data. It goes without saying that network connectivity between the Self-Hosted Integration Runtime and the SAP system is essential for data extraction to work. Such an architecture allows replicating the data no matter where your SAP system is deployed – on-premises or in any cloud.
The new SAP CDC connector uses the Mapping Data Flow functionality to automatically merge subsequent delta extractions into a consistent data store. Whenever you extract new and changed information, you must carefully analyze how to treat it in relation to the target datastore. Plain inserts are insufficient – you must take care of all CRUD operations and respectively update the target storage. Otherwise, you’ll end up with inconsistencies: duplicated rows (for records updated in SAP) or lines that should not exist any longer (for records deleted from the SAP system). This is where the Mapping Data Flow comes into place. It uses the Spark engine and a set of rules to combine all extracted records together without any additional activity from your side. This job requires Azure Integration Runtime (in addition to Self-Hosted Integration Runtime, which takes care of the data extraction part of the process).
The target can be any data store supported by the Azure Data Factory. However, the target store has to support Upserts and deletes to use the automatic delta merge process. If you’d like to keep data in the lake, you can use Delta as the format (and this is what I use in this post). If you use the traditional parquet format, the merge process won’t work, and you’ll have to implement it manually as a post-processing step. Of course, you can also use any relational database like SQL Server.
DEPLOYING INTEGRATION RUNTIME
The Self-Hosted Integration Runtime uses the SAP proprietary RFC protocol to communicate with the Operational Data Provisioning framework. Therefore, it requires the SAP .NET libraries to be installed on the same server to initiate the connection. You can download it from here:
SAP Connector for Microsoft .NET
I suggest always using the latest version available. During the installation, choose to Install Assemblies to GAC. Otherwise, the Self-Hosted Integration Runtime won’t find these libraries, and the connection to the SAP system will fail.
Once you have the .NET libraries on the server, you can download and install the Self-Hosted Integration Runtime.
Download Microsoft Integration Runtime from Official Microsoft Download Center
Similarly, to the .NET libraries, the Self Hosted Integration Runtime installation is effortless and shouldn’t take more than 10 minutes. Before starting to use it, it must be register in the Azure Data Factory.
- Go to the Manage section in Azure Data Factory, choose Integration Runtimes and click the +New button.
- Follow the wizard. Choose the “Azure, Self-Hosted” option and click continue. In the next step, on the Network Environment screen, choose “Self-Hosted”.
- Choose the name of the Integration Runtime and click Create. Copy the displayed authentication key.
- Go back to the server with the Self-Hosted Integration Runtime. Once the installation completes, provide the authentication key. Paste it and click Register.
- After a few minutes, you can see the newly deployed Integration Runtime in the Azure Data Factory. The status “Running” means the installation was successful, and you can start using it to copy data.
- Click the +New button again to deploy the Azure Integration Runtime. Choose the Azure, Self-Hosted” option again, but in the next step, select Azure instead of Self-Hosted. Provide the name of the Integration Runtime.
- In the Data Flow Runtime tab, configure the compute size – recommendation is to choose at least Medium. However, the target size depends on many factors, like the number of objects to replicate, desired concurrency or amount of data to copy. Confirm your changes by clicking Create button. After a short while, you can see Integration Runtime in Azure Data Factory.
Once Integration Runtimes ready, define Linked Services.
CREATE LINKED SERVICES
A linked service defines the connection to the desired resource – for example, SAP system, data lake or SQL database. Treat it like a connection string that stores all details required to initiate communication with an external system: the system type, its hostname or IP address, and credentials to authenticate. Define Linked Service in the Manage section of the Azure Data Factory:
- Click +New button. Filter the list of available data stores and choose SAP CDC.
- Provide the name of the linked service and all connection details to SAP system, including the system number and client id. In the field “Connect via integration runtime”, choose previously deployed Self-Hosted Integration Runtime. Recommendation – to increase the security of the solution, consider using Azure Key Vault to store the password instead of typing it directly to ADF.
- In the Subscribed name, define the unique identifier that can be used later to track delta extraction in SAP.
- Click Test Connection to verify everything works fine.
Once the source and target system are defined, we can move to the next step.
CREATE DATAFLOW
The dataflow allows to extract and transform data. In the simplest form, it requires two actions:
- Source – that copies data from the source system and applies deduplication process (necessary in delta extraction, when there are multiple changes to the same record)
- Sink – that saves extracted data to the desired location and merges multiple delta extractions.
In the Author section of the Azure Data Factory create a new dataflow. Choose Add Source in the designer:
There are six tabs that you can use to configure the extraction process.
- In the Source Settings, change the Source type to Inline, choose SAP CDC as the inline dataset and select the Linked Service pointing to the SAP system.
- When you move to the Source Options tab, you can configure the extraction process. The ODP Context field describes the type of object you want to process. Multiple object types are available, including Extractors, CDS Views or SLT. To enable delta extraction set the Run mode to “Full on the first run, then incremental” and choose the Key Columns – in many cases, Azure Data Factory automatically fetches key columns. For extractors, however, SAP doesn’t expose information about key columns, so have to provide them manually.
- In the Projection tab, import the data schema, which allows to change the default type mappings and simplifies working with the dataset if there is need to add any transformations. The debugger must be running to import Projections.
- The Optimize tab allows you to define partitions and selection criteria if you want to filter data based on column value, for example, fetching only records for a single company code.
- Now, let’s take care of the target datastore. In the designer window, add a new action by clicking the small + button. Choose Sink to provide the target location for extracted data. Similarly, to the source, a couple of tabs are available that let you configure the target datastore. Change the Sink type to Inline and choose Delta as the dataset type.
- Move to the Settings tab. Provide the target file path. Change the Update Method to allow deletes and Upserts. Provide a list of Key Columns used in the data merge process. In most cases, unless you defined some additional actions to change the schema, they are the same as defined in the Source.
That’s it. Using above mentioned steps simple dataflow is created that extracts data from a selected SAP object. The last thing left to do is create the pipeline that triggers the dataflow execution.
CREATE PIPELINE
Create a new Pipeline in the Author section of the Azure Data Factory. From the list of available actions, expand the Move and Transform section.
- Choose Data Flow and drag it to the designer.
- In the Settings tab, choose the previously created data flow.
- Choose the Azure Integration Runtime created at the beginning of the process.
- Expand the Staging property and choose Linked Service and the file path used as a staging area.
That’s it! The configuration of all required components to extract data from the SAP system. Click the Publish button to save all settings.
EXECUTION AND MONITORING
It’s time to verify that the whole configuration is correct.
- To run the extraction, choose the Add Trigger in the pipeline view and select Trigger Now.
- Depending on the source table size, it takes a couple of minutes to extract data. Once the extraction finishes, the Pipeline status changes to Succeeded. Monitor the process in the Monitor section.
- Drill down and see detailed information for any step within the data flow. Find the details of SAP system there, which includes if Azure Data Factory successfully copied all of them or not. And display extracted data in Synapse.
geetha.s



{kind=link}