Streamlining Data Ingestion with Databricks Auto Loader
Blogs

Enhancing Resume Quality with Intelligent ATS Screening Techniques
June 27, 2025Using Azure Data Factory to Copy SharePoint List Data to Blob Storage
July 16, 2025
In a world where data is constantly pouring in from all directions, getting that data into your system quickly and efficiently is more important than ever. Whether it’s logs, JSON files, or data from cloud storage, businesses today need real-time access to stay ahead.
That’s where Databricks Auto Loader comes in. It’s a smart, hands-off tool that takes the headache out of setting up data pipelines automatically detecting new files and streaming them right into your Lakehouse with ease and scale. Whether you’re just starting out or managing tons of data, Auto Loader helps you spend less time worrying about ingestion and more time unlocking insights.
1. What Is Databricks Auto Loader?
Databricks Auto Loader is a feature in Databricks that helps you to automatically detect and load new files from cloud storage (like AWS S3, Azure Data Lake, or GCS) into Delta Lake tables in a streaming or incremental way.
2. Why use Databricks Auto Loader?
- Instantly Detects New Files
No need for manual checks or complex schedules, Auto Loader picks up new data as soon as it lands. - Built to Scale
Handles millions of files efficiently, even in large and messy directories, with low latency and high reliability. - Handles Changing Data
Automatically adapts to evolving file formats, perfect for semi-structured data like JSON and CSV. - Seamless with Delta Lake
Writes directly to Delta tables with support for ACID transactions, versioning, and time travel. - Optimized for Cost
File notification mode reduces the need for costly directory scans, saving compute and money.
3. Autoloader supports two File Detection modes:
- Directory Listing Mode
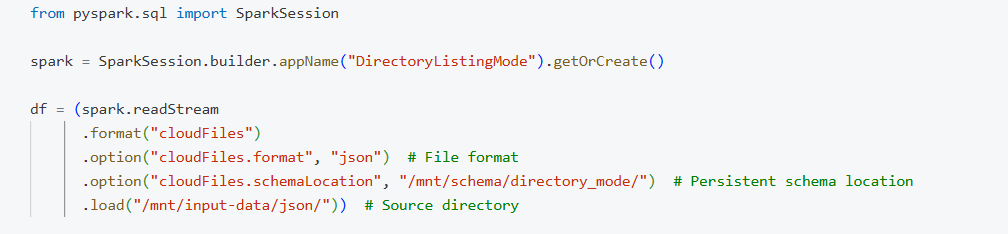
Databricks Auto Loader offers Directory Listing Mode as its default file detection method. In this mode, Auto Loader regularly scans the input directory to find any new files that have been added. It’s simple to configure and requires only read access to the cloud storage, making it ideal for small to medium datasets where file arrivals are not too frequent.
Example: Ingesting JSON files using Directory Listing Mode
2. File Notification Mode
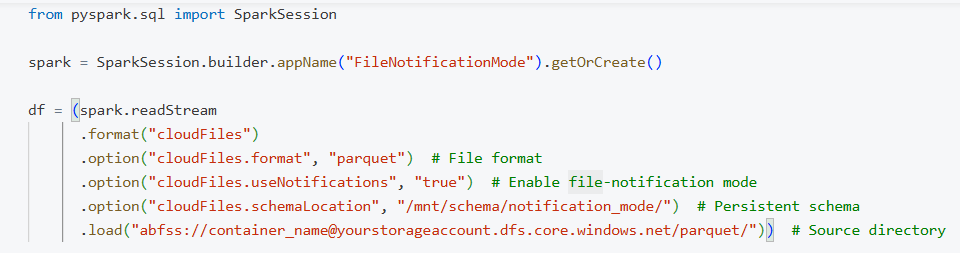
The second option is File Notification Mode, which is more efficient for high-volume or frequent data ingestion. Instead of scanning folders, it relies on cloud-native services like AWS SNS/SQS or Azure Event Grid with Queue Storage to get real-time alerts when new files are added. This approach enables faster processing but involves additional setup and requires both read and write permissions to the storage and related cloud services.
Example: Ingesting Parquet files using File Notification Mode on Azure
Note: For file notification mode to work:
- You must configure Event Grid + Queue Storage and allow Databricks to access them.
- Permissions: The service principal must have Contributor or equivalent access to both Event Grid and Queue.
To know more about the options available in Auto Loader feature. Refer the following link.
Auto Loader makes easy to work with changing data by automatically handling new columns as they appear in your files, no need to manually update the schema. This is especially helpful when you’re dealing with flexible formats like JSON or CSV, where the structure of incoming data can change over time. It saves time and effort by adapting to these changes on its own.
For more information use the below link:
https://learn.microsoft.com/en-us/azure/databricks/ingestion/cloud-object-storage/auto-loader/schema
4. Conclusion:
Databricks Auto Loader makes real-time data ingestion easy and reliable. With minimal setup, it lets you focus on insights instead of managing files. If you’re using Databricks or planning to upgrade your ETL process, Auto Loader is a smart choice.
Pallavi A
{kind=link}