Understanding Apache Iceberg: The Architecture and Features
Blogs

Why Druid’s index_parallel is the Future of Batch Ingestion
August 15, 2025
The Rollup Revolution: Druid vs. Modern Analytics
September 7, 2025
Introduction to Iceberg Table
Imagine you have a huge library of books, but the card catalog is a mess. It has missing entries, some cards are duplicates, and others point to the wrong shelf. Trying to find a book would be a nightmare, right? That’s what a traditional data lake can feel like. Apache Iceberg is an open-source table format that acts as a reliable, high-performance catalog for your data lake. It brings the power of a database table, like ACID transactions and schema evolution, to massive datasets stored in object storage like Amazon S3 or Google Cloud Storage.
Why Iceberg? The Problems It Solves
Before Iceberg, traditional data lake management often relied on formats like Apache Hive, which had significant limitations when dealing with petabyte-scale data. Hive’s approach of managing data as files in folders created several problems:
- Slow Query Planning: To run a query, the query engine had to list all the files in a directory, which was extremely slow for tables with millions of files.
- Corrupted Data on Failure: A failed write operation could leave a table in an inconsistent state with partial changes, making it difficult to recover and leading to unreliable data.
- Inefficient Schema Evolution: Evolving a table’s schema (e.g., adding or renaming a column) often required rewriting the entire table, a costly and time-consuming process.
- Hidden Partitioning: Users had to know the table’s physical partition layout to write efficient queries, which was difficult to manage and prone to human error.
- Reliability issues: Operations like writes and updates weren’t always atomic, meaning a failed write could leave the table in an inconsistent state.
Iceberg was introduced to fix these issues by treating a table as a collection of data files, managed by a sophisticated metadata layer, rather than a collection of folders. This design allows it to provide database-like features directly on your data lake.
Architecture of Iceberg Table
The core of Apache Iceberg’s architecture is its metadata layer, which acts as a database-like catalog on top of a data lake. Instead of managing data as files in a folder, Iceberg treats a table as a collection of snapshots. Each snapshot points to a complete set of data files, allowing for reliable and performant operations.
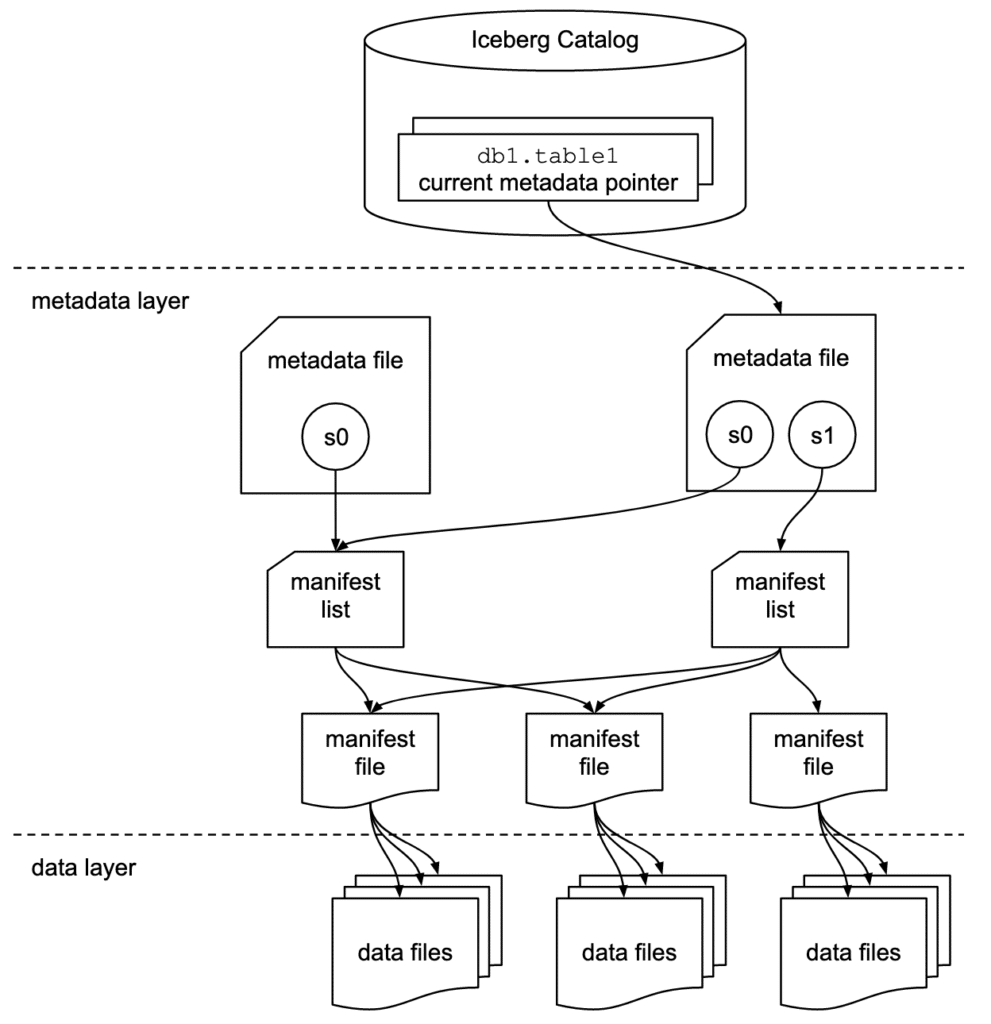

Key Components
1. Catalog
The Catalog is the central point of contact for any query engine. It’s the highest-level metadata store, a database or service that keeps track of the current state of a table. When a user wants to read or write to an Iceberg table, the query engine first asks the catalog for the table’s location and the ID of its current snapshot. This is a very fast operation, regardless of the table’s size.
2. Metadata Layer
This is the heart of Iceberg. The metadata layer is made up of a nested structure of files, each with a specific purpose:
- Metadata File: This file points to a list of snapshots. Every time a change is committed to the table (e.g., a new write or an update), a new metadata file is created.
- Snapshot: A snapshot represents the state of the table at a specific point in time. It’s an immutable record that points to a list of manifest lists. This is what enables “time travel.”
- Manifest List: A manifest list is a file that contains a list of manifest files. It also includes summary information, like the number of data files and rows, which helps the query engine prune entire manifests without having to read them.
- Manifest File: This is the most detailed file in the metadata layer. It contains the list of actual data files for the table, along with rich statistics for each file, such as column-level value ranges, row counts, and data file paths.
3. Data Files
The actual data is stored in open formats like Parquet, ORC, or Avro. The manifest files in the metadata layer contain the paths to these data files on object storage (like S3 or GCS) or HDFS. Iceberg does not manage the data files themselves; it only manages the pointers to them, which makes it format-agnostic.
How It Works: A Simple Query Flow
When a query engine like Spark or Trino wants to read an Iceberg table, it follows a simple and efficient process:
- The engine asks the Catalog for the current table metadata.
- The Catalog returns the path to the current Metadata File.
- The engine reads the Metadata File to get the latest Snapshot.
- The engine then reads the Manifest List from the snapshot. Using the summary statistics in the manifest list, it can prune entire groups of manifest files that are not relevant to the query.
- Next, the engine reads the relevant Manifest Files. Using the rich statistics (like column value ranges) in these files, it prunes the data files themselves. For example, if a query is for “date = ‘2023-01-01’,” the engine can quickly identify only the files that contain data for that date.
- Finally, the engine reads the Data Files that were not pruned and returns the results to the user.
This architecture ensures that query planning is extremely fast, as the engine only has to read a few small metadata files to determine which large data files to scan. This is a significant improvement over traditional data lake approaches that require listing a directory of potentially millions of files.
Key Features of Iceberg Tables
Iceberg’s design is based on a snapshot-based querying model, where each change to a table creates a new, immutable snapshot of the table’s state. This core concept enables its most powerful features.
- ACID Transactions: Iceberg provides Atomicity, Consistency, Isolation, and Durability, ensuring that writes are all-or-nothing. This means multiple users can safely read and write to the same table concurrently without corrupting data.
- Schema Evolution: You can add, drop, rename, or reorder columns without rewriting the underlying data. Iceberg manages these changes at the metadata level, ensuring that old data files remain compatible with the new schema.
- Hidden Partitioning: This feature abstracts the physical partitioning of data from the user. You can query a table without knowing how it’s partitioned, and Iceberg’s query engine will automatically prune unnecessary data files, significantly speeding up queries.
- Time Travel: Because Iceberg maintains a history of table snapshots, you can query a table as it existed at a specific point in time. This is invaluable for historical analysis, debugging data issues, and recovering from accidental data deletions.
Let’s walk through a simple example using Apache Spark to demonstrate some of Iceberg’s features.
Set up Spark and Iceberg:
# Set up a new Spark session with Iceberg dependencies pyspark --packages org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.0.0.
Create an Iceberg Table:
from pyspark.sql import SparkSession
# Start a Spark session
spark = SparkSession.builder.appName("IcebergExample").getOrCreate()
# Create a simple DataFrame
data = [
("john", 30),
("jane", 25),
("peter", 40),
]
columns = ["name", "age"]
df = spark.createDataFrame(data, columns)
# Create an Iceberg table
df.writeTo("iceberg_db.people").create()
Perform an Update (ACID Transaction):
# Update Jane's age to 26
spark.sql("UPDATE iceberg_db.people SET age = 26 WHERE name = 'jane'")
Time Travel to a Previous Snapshot:
# Get the ID of the previous snapshot
snapshot_id = spark.sql("SELECT snapshot_id FROM iceberg_db.people.history ORDER BY committed_at DESC LIMIT 1 OFFSET 1").first()["snapshot_id"]
# Query the table using the previous snapshot ID
spark.sql(f"SELECT * FROM iceberg_db.people VERSION AS OF {snapshot_id}").show()
You’ll see the original data where “jane” has an age of 25.
Schema Evolution:
# Add a new column 'city'
spark.sql("ALTER TABLE iceberg_db.people ADD COLUMNS (city STRING)")
You can now query the table, and the new column will appear, even for the old data. Iceberg handles this behind the scenes.
Real-World Use Cases
Imagine a large e-commerce company. They handle millions of customer orders every day.
- ACID Transactions: When a customer places an order, the company needs to update multiple systems: inventory needs to decrease, the customer’s order history needs to be updated, and a new shipping record needs to be created. Iceberg’s ACID properties ensure that all these updates either succeed completely or fail completely, preventing a situation where a customer’s credit card is charged but the order never goes through.
- Time Travel: Let’s say a data analyst accidentally runs a script that deletes the order records for a specific day. With Iceberg’s time travel feature, they can simply query the table as it existed an hour before the script ran, retrieving all the “lost” data without needing to restore from a backup.
- Schema Evolution: Over time, the company decides to start collecting new information about each order, such as the customer’s preferred delivery slot. With Iceberg, they can simply add a new column to the orders table without having to rewrite years of historical data. The old records will simply have a null value for the new column, and the new records will have the delivery slot information.
Companies across various industries have adopted Apache Iceberg to build robust and scalable data lakehouse.
- Netflix: The original creator of Iceberg, Netflix uses it to manage its massive-scale data analytics, enabling efficient and reliable data pipelines for everything from user behavior to content recommendations.
- Apple: Apple uses Iceberg to power its data analytics platform, allowing engineers to work with petabyte-scale datasets while ensuring data consistency and reliability.
- AdTech and IoT: Companies in these sectors handle massive streams of event data (clicks, sensor readings). Iceberg’s ability to handle frequent, small writes and schema changes without performance degradation makes it an ideal choice.
- Financial Services: Banks and insurers use Iceberg’s time travel and ACID properties for auditing and regulatory compliance, ensuring a reliable, immutable history of transactions.
Conclusion:
Apache Iceberg is more than just a file format; it’s a transformative technology that brings the best of data warehouses and data lakes together. By providing a reliable, performant, and flexible table format, it empowers organisations to unlock the full potential of their data. As the demand for sophisticated data analytics continues to grow, Iceberg is becoming an essential tool for building the next generation of data platforms.
Gajalakshmi N



{kind=link}