Upsert Functionality in Azure Data Factory.
Blogs
LangChain: Simplifying LLM Development for Next-Gen AI Applications
March 7, 2024
Data Migration – MySQL >> MongoDB
March 11, 2024Upsert Functionality in Azure Data Factory.
Azure Data Factory (ADF) is a cloud-based ETL/ELT (Extract, Transform, Load/Extract, Load, Transform) orchestration service that simplifies data integration tasks across various cloud and on-premises sources. One of its valuable functionalities is the ability to perform upserts (insert or update) on data within your Azure SQL Database. This blog post talks about how ADF’s upsert process works, looks at ways to make it better, and explores advanced options for getting the best performance.
Understanding ADF’s Upsert Mechanism:
When you configure a copy activity in ADF to perform Upserts based on primary keys, ADF employs a two-step approach designed for efficiency and data integrity:
- Interim Staging: ADF creates a temporary table, typically within the dbo schema of your Azure SQL Database. This interim table serves as a staging area for the incoming data. To facilitate internal management of the upsert process, ADF adds a column named BatchIdentifier to this temporary table.
- Batch-wise Updates/Inserts: Following the data load into the interim table, ADF performs batched updates or inserts into your target table. The data is processed based on the defined primary key constraint. The default batch size is determined dynamically by ADF, considering factors like network bandwidth and data volume. However, you have the flexibility to adjust this value for tailored performance.
Optimizing Batching for Upsert Efficiency:
The default batch size chosen by ADF might not always yield the most efficient outcome for your specific scenario. Here’s how you can take control and fine-tune it for optimal performance:
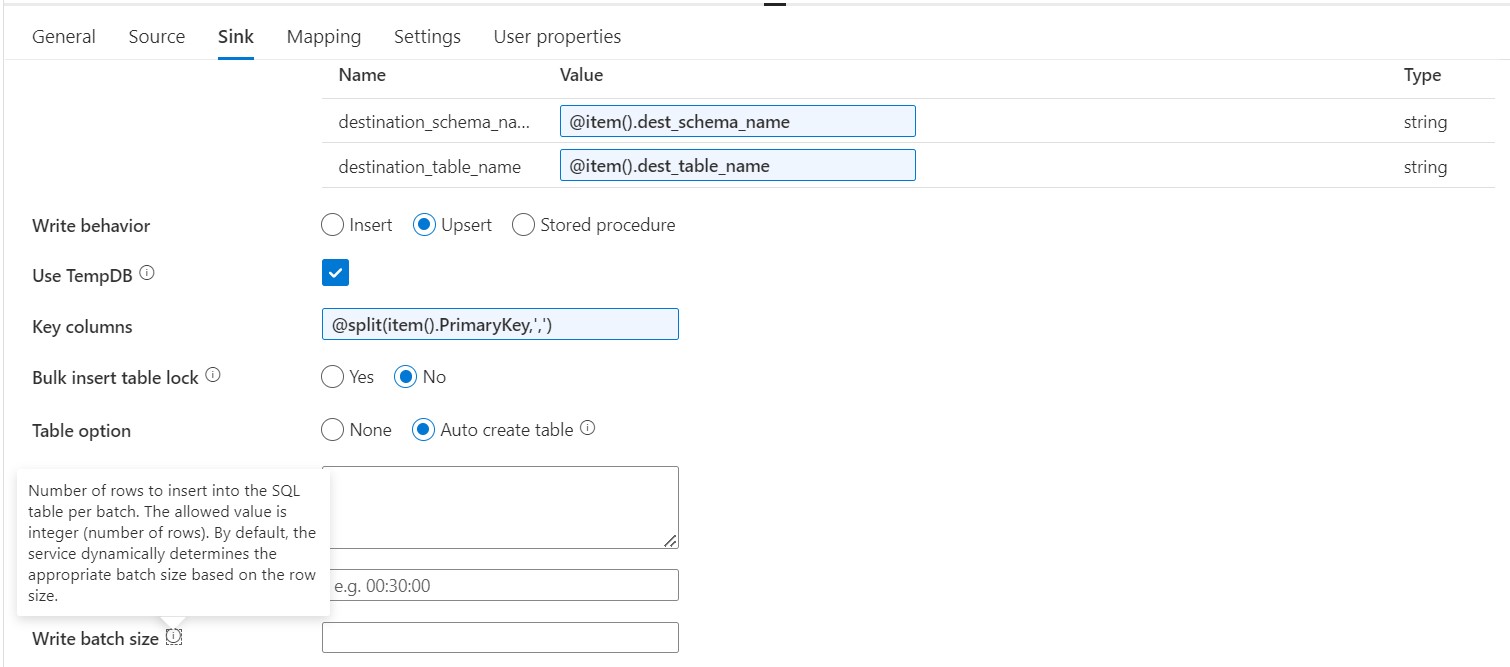
- Leveraging the writeBatchSize Property: Within the copy activity settings, locate the writeBatchSize property. This property allows you to specify the number of rows (as an integer value) that will be inserted into your target table per batch. Setting an appropriate writeBatchSize value can significantly impact the upsert operation’s performance. A larger batch size can improve overall throughput but might consume more memory resources. Conversely, a smaller batch size can reduce memory usage but potentially increase the total execution time. Experimenting with different writeBatchSize values can help you identify the optimal setting for your specific workload.
- Monitoring and Adjusting Batch Size: ADF provides monitoring capabilities that allow you to track the performance of your copy activities. By monitoring metrics like data processing time and resource utilization, you can assess the effectiveness of your chosen writeBatchSize value. If you observe slow processing times or resource constraints, consider adjusting the batch size accordingly.
Advanced Control with Stored Procedures (Optional):
While ADF’s internal BatchIdentifier cannot be directly modified, you have a powerful alternative for advanced control over batching behavior:
Crafting a Stored Procedure: Create a stored procedure within your Azure SQL Database. This procedure can accept the BatchIdentifier as an input parameter. You can then design the logic within the stored procedure to handle updates and inserts based on your specific requirements. This approach allows for more granular control over the upsert process, including custom error handling and advanced data manipulation logic. Finally, configure your copy activity to utilize this stored procedure as the sink for the upsert operation.
Example Stored Procedure:
CREATE PROCEDURE [dbo].[InsertOrUpdateData]
@BatchIdentifier INT
AS
BEGIN
SET NOCOUNT ON;
MERGE INTO [dbo].[TargetTable] AS target
USING [dbo].[InterimTable] AS source
ON target.[PrimaryKey] = source.[PrimaryKey]
WHEN MATCHED THEN
UPDATE SET
target.[Column1] = source.[Column1],
target.[Column2] = source.[Column2],
…
WHEN NOT MATCHED THEN
INSERT ([PrimaryKey], [Column1], [Column2], …)
VALUES (source.[PrimaryKey], source.[Column1], source.[Column2], …);
END
Important Note: Modifying the internal BatchIdentifier is strictly not recommended, as it can disrupt ADF’s internal management of the upsert process. The stored procedure approach offers a more controlled and adaptable way to manage batching behavior while seamlessly integrating with ADF’s upsert functionality.
Choosing the Right Approach:
The decision of whether to leverage the writeBatchSize property or implement a stored procedure depends on your specific needs. For basic upsert scenarios where optimizing the default batch size is sufficient, adjusting the writeBatchSize property might be the simpler approach. However, if you require more granular control over the upsert process, custom error handling, or advanced data manipulation logic, creating a stored procedure offers greater flexibility.
Conclusion:
By understanding the inner workings of ADF’s upsert process and strategically utilizing the writeBatchSize property or stored procedures, you can significantly enhance your data integration workflows and achieve efficient upserts within your Azure SQL Database. This empowers you to manage large datasets effectively, streamline your data management processes, and ensure data consistency. With ADF’s upsert functionality and the optimization techniques discussed here, you can ensure your data pipelines operate at peak performance.
Geetha S



{kind=link}